
Having surveyed the relationships of computer science with other disciplines, it remains to answer the basic questions: What is the central core of the subject? What is it that distinguishes it from the separate subjects with which it is related? What is the linking thread which gathers these disparate branches into a single discipline? My answer to these questions is simple -- it is the art of programming a computer. It is the art of designing efficient and elegant methods of getting a computer to solve problems, theoretical or practical, small or large, simple or complex. It is the art of translating this design into an effective and accurate computer program.
C.A.R. Hoare
Essays in Computing Science
Computer Science is the first engineering discipline in which the complexity of the objects created is limited solely by the skill of the creator, and not by the strength of raw materials.
Brian K. Reid
Communications of the ACM, October 1987
In theory, there is no difference between theory and practice. But, in practice, there is.
Jan van de Snepscheut
GIGA Quotes, GIGA-USA.com
Computer science is a relatively young field of study, with electronic computers only dating back some fifty years. Certainly, computational devices and theories existed before then (see Chapter 6), but the culmination of technology and theory that is recognized as the birth of the field took place in the middle of the 20th century. Computer science's youth is especially notable compared to more traditional sciences such as biology and chemistry, which trace their roots back hundreds or even thousands of years. Still, the impact that computers and their study has made on our society in such a short period of time is astounding.
This chapter presents an overview of computer science as a discipline, emphasizing its common themes (hardware, software, and theory) as well as its diversity. As we will see, computer science is much more than just the study of computers. It encompasses all aspects of computation, from the design and analysis of problem solutions, to the design and construction of computers to carry out those solutions. To ensure a broad appreciation for the discipline, various subfields of computer science will be described.
While the importance of computer technology was apparent almost immediately after its introduction in the late 1940s, the field of computer science was slow to gain acceptance among the scientific community. Computer science was not recognized as a separate field of study at most colleges and universities until the 1970s or even 1980s. Many still argue that computer science is not really a science in the same way that biology and chemistry are. In fact, while computer science does have much in common with the natural sciences, it also has close ties with other fields such as engineering and mathematics. This interdisciplinary nature has made computer science a difficult field to classify. Biology can be neatly described as the study of life, while chemistry can be described as the study of chemicals and their interactions. Is computer science, as the name suggests, simply the study of computers?
Although computers are the most visible feature of computer science, it would be inaccurate to define the field entirely in terms of machinery. A more descriptive definition would be to say that computer science is the study of computation. The term computation denotes more than just machinery, it encompasses all facets of problem solving. This includes the design and analysis of algorithms: step-by-step instructions for accomplishing specific tasks. It also includes the formalization of algorithms as programs, and the design and manufacture of computational devices for executing those programs. In addition, a strong theoretical understanding of the power and limitations of algorithms and computational models is also a key factor in making computer science a well-rounded field.
Whether this combination of problem solving, engineering, and theory constitutes a "science" is a matter of interpretation. Some define "science" as a rigorous approach to understanding complex phenomena and solving problems. The methodology for understanding phenomena, commonly referred to as the scientific method, may be summarized as an algorithm (Figure 8.1).
|
|
Based on this definition, much of what computer scientists do may be classified as "science". Designing and analyzing algorithms for solving problems involves a rigorous approach based on the scientific method. In particular, verifying the behavior of an algorithm requires forming hypotheses, testing those hypotheses (either through experimentation or mathematical analysis), and revising the algorithm based on the results. For example, the designer of an algorithm for accessing a large database of records would need to form hypotheses as to its behavior under various conditions, test those hypotheses by executing the algorithm on actual data and/or via mathematical analysis, and finally revise the algorithm if it fails to meet expectations. Similarly, the design and testing of complex software (say, programs consisting of thousands or millions of lines of code) and hardware systems (say, circuitry consisting of millions of transistors) requires a rigorous, experimental approach to fully understand their behavior.
What does set computer science apart from the natural sciences, however, are the types of phenomena being studied. The natural sciences, and even many of the social sciences, are concerned with studying complex, natural phenomena. The underlying assumption is that there are natural laws that define the way matter behaves, the way chemicals react, the way life evolves, and even the way people interact. Sciences such as physics, chemistry, biology, and psychology strive to understand natural phenomena and extract the underlying laws that control behavior. In computer science, the systems being studied are largely artificial. Algorithms, programs, and computers are designed and built by people. When a computer scientist analyzes the behavior of a program on a particular computer, she is essentially attempting to understand it within the artificial world of that machine. By devising a new computer or other model of computation, computer scientists have the ability to create their own artificial laws that affect how systems behave. To capture this distinction, Herbert Simon coined the phrase "artificial science" to distinguish computer science from the "natural sciences".
In Europe, the question of whether computer science is a science is often avoided by calling the field "Informatics" or "Information Systems". This name suggests that information processing is central to the field, not the machinery for processing that information. Donald Knuth, the noted computer scientist and author of The Art of Computer Programming, has suggested the alternative name "Algorithmics", which emphasizes the central role of algorithms in computation. Regardless of the name, however, the research and technology developed by the discipline of computer science have changed and will continue to impact all of our lives
Since computation encompasses so many different types of activities, the research conducted by computer scientists is often difficult to classify. Despite the differences, however, there are three recurring themes that appear throughout the discipline: hardware, software, and theory. Some computer scientists focus on hardware, designing and building computers and related technology. Others focus on software, the composition and encoding of algorithms that can then be executed on computers. Still others attack computation from a theoretical standpoint, striving to understand the foundations of the discipline. Although it is possible to find computer scientists who classify themselves entirely in one of these areas, it is much more common to find a combination of all three in any research (Figure 8.2).
|
As we saw in Chapter 1, the term hardware refers to the physical components of a computer and its supporting devices. Most modern computers have the same basic layout, known as the von Neumann architecture, consisting of the Central Processing Unit (CPU), memory, and input/output devices. Working together, these components form a general-purpose machine that can store and execute programs for accomplishing various tasks.
Although the basic architecture of most computers is very similar, there are numerous areas of active research in the design and organization of computer hardware. Computer scientists working in circuit design and microchip manufacturing must draw on expertise from chemistry, particle physics, and mechanical engineering to squeeze millions of transistors on a microchip the size of a dime. Systems architects study different ways of connecting components to increase computational throughput, including parallel computing where multiple CPUs are used to divide the computational burden. And as the rapid growth of the Internet attests, different ways of networking separate computers in order to share information and work together is possibly the greatest opportunity for growth in computing power and accessibility.
In contrast to hardware, software refers to the programs that execute on computers. Most people in the computer industry work on the software side, in positions such as programmer, systems analyst, or software engineer. In fact, the software industry continues to be one of the fastest growing facets of the U.S. economy.
Software can be divided into three different classes, based on its purpose and intended audience. Systems software encompasses those programs that directly control the execution of hardware components. For example, an operating system includes software for managing files and directories, linking programs with hardware devices such as printers and scanners, and processing user inputs such as keystrokes and mouse clicks. Development software encompasses programs that are used as tools in developing other programs. For example, Visual Studio by Microsoft and CodeWarrior by Metroworks are development environments for creating and executing program using a variety of languages (e.g., C++, Java). Finally, applications software encompasses all other programs, which cover a wide variety of applications. Examples of applications software include Web browsers such as Internet Explorer and Netscape Navigator, word processors such as Word and WordPerfect, presentation tools such as PowerPoint and FrameMaker, editors such as NotePad and emacs, and games such as Solitaire and Doom.
Just as there is a wide spectrum of applications for software, there is also a wide variety in the types of work computer scientists perform on the software side. Some computer scientists are more theoretical, focusing on the development and analysis of algorithms. They study general approaches to problems, and strive to understand the complexity of different problems and their solutions. These "software people" may never write a program in their lives! Others study and develop different programming languages that allow for greater ease and productivity in solving classes of problems. But perhaps the most common view of a computer scientist is that of a programmer, one who designs algorithms and encodes them into a particular programming language for execution on a computer.
Just as there may be computer scientists who study algorithms but never write a program, there may be others who never even touch a computer. Computer science, in addition to being about hardware and software, is concerned with the study of methods of computation. Theoretical computer scientists, whose work often overlaps with mathematics and formal logic, study different models of computation and strive to understand the power and limitations of algorithms and computers.

|
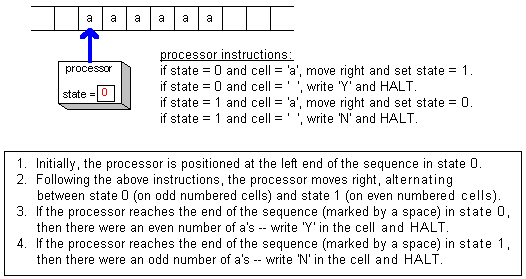
|
While Turing machines may seem simplistic, they have been shown to be as powerful as the modern computers of today. That is, any computation that can be programmed and performed using a modern computer could be programmed and performed by a Turing machine. Of course, the equivalent Turing machine program might be much more complex and the number of steps required might be much larger, but the Turing machine would eventually complete the task. The advantage of having a simple model such as the Turing machine is that it serves as a manageable tool for studying computation and algorithm efficiency. In fact, Turing was able to use the Turing machine model of computation to prove a rather astounding result: there exist problems whose solutions cannot be computed. That is, there are problems that are not solvable using algorithms or any computing device. The most famous such problem is referred to as the Halting Problem, and was proven to be noncomputable by Turing in 1930. In programming terminology, the Halting Problem states that you can't write a program that determines in all cases whether another program will halt. As you will see in Chapter 13, the ability to add conditional repetition, code that is repeated as long as some condition holds, to programs is a powerful algorithmic tool. However, conditional repetition raises the potential for programs that loop forever. Using the Turing machine as his model of computation, Turing was able to prove that it is impossible to write a program (i.e., algorithm) that is guaranteed to recognize every program (i.e., algorithm) with an infinite loop.
In general, theoretical computer science attempts to understand computation independent of any particular machine architecture, and so provide a strong foundation for the development new algorithms and computers.
In Computer Science: The Discipline, Peter J. Denning identified 12 major subfields of computer science (Figure 8.5). Each subfield represent a unique viewpoint and approach to computation, often with close ties to other disciplines such as physics, psychology, and biology. However, the common themes of computer science, hardware, software, and theory, are still central to each subfield.
| Algorithms and Data Structures | The study of methods for solving problems, designing and analyzing algorithms, and effectively using data structures in software systems. |
| Architecture | The design and implementation of computing technology, including the integration of effective systems and the development of new manufacturing methods. |
| Operating Systems and Networks | The design and development of software and hardware systems for managing the components of a computer or network of communicating computers. |
| Software Engineering | The development and application of methodologies for designing, implementing, testing, and maintaining software systems. |
| Artificial Intelligence and Robotics | The study and development of software and hardware systems that solve complex problems through seemingly "intelligent" behavior. |
| Programming Languages | The design and implementation of languages that allow the user to express ideas and algorithms and effectively execute those algorithms on computers. |
| Databases and Information Retrieval | The organization and efficient management of large collections of data, including methods for searching and recognizing patterns among the data. |
| Graphics | The design of both software and hardware systems for representing physical and conceptual objects visually, as with images, video, or 3-dimensional holograms. |
| Human-Computer Interaction | The design, implementation, and testing of interfaces that allow users to more effectively interact with computing technology. |
| Computational Science | Explorations in science and engineering that utilize high-performance computing, such as modeling complex systems or simulating experimental conditions. |
| Organizational Informatics | The development and study of management processes and information systems that support technology workers and organizations. |
| Bioinformatics | The application of computing methodologies and information
structures to the biological sciences, such as the characterization and analysis of
the human genome.
|
The following sections provide an overview of five of the most visible subfields of computer science, Algorithms and Data Structures, Architecture, Operating Systems and Networks, Software Engineering, and Artificial Intelligence and Robotics. While a complete description of these subfields is impossible in such a short space, a summary of key ideas, as well as a representative example from that subfield, are provided for each.
The subfield of Algorithms and Data Structures is concerned with developing, analyzing, and implementing algorithms for solving problems. Since algorithms are fundamental to all of computer science (see Chapter 10), researchers in this subfield may approach the topic from different perspectives. A theoretical computer scientist might be concerned with analyzing the characteristics, efficiency, and limitations of algorithms. Understanding which types of algorithms are best suited to certain tasks leads to more effective problem solving. Since programs are the implementations of algorithms, software development is driven by an understanding and mastery of algorithms. Algorithms and the data structures they manipulate are the tools a programmer uses when designing software to solve problems. Most programming languages provide extensive libraries of data structures and algorithms, making the programmer's job easier. Ultimately, programs must be executed by computers, so the connection between algorithms and the underlying hardware of the machine must be understood.
One application area where the design of new algorithms has had great impact is encryption. Encryption is the process of encoding a message so that it may be understood by its intended recipient but not by anyone else intercepting that message. Since the time of Julius Caesar, various algorithms have been used to encode secret messages, for military, political, and even commercial security. For example, Caesar was known to use an algorithm that replaced each letter in the message with the letter three positions later in the alphabet. Thus, the phrase "ET TU BRUTE" would be encoded as "HW WX EUXWH", since 'H' is three positions later than 'E', 'W' is three positions later than 'T', and so on. Of course, in order for the message to be decoded, the recipient must know the method by which it was encoded, and then perform the reverse translation.
Caesar's algorithm is known as a private key encryption algorithm since it relies on the sender and recipient sharing a secret key (in this case, knowing that letters are shifted three positions). While Caesar's algorithm is not very secure by modern standards, there are more complex algorithms in use today that make decoding a message essentially impossible without knowing the key. The Digital Encryption Standard (DES), for example, utilizes a 56-bit number as the key. Without knowing the key, decoding the message is virtually impossible, as it requires trial-and-error on 256 = 72 quadrillion (72 x 1015) possible keys. The general process of encoding, sending, and decoding a message using public key encryption is illustrated in Figure 8.6.
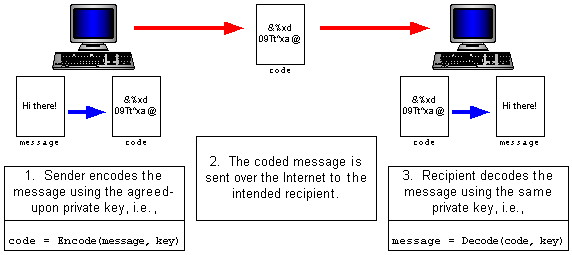
|
Private key encryption algorithms rely on the fact that the sender and recipient have agreed upon the secret key ahead of time. The exchange of keys for private key encryption introduces a new security concern, however, as any person that intercepts the key will be able to decode subsequent messages. For companies or government agencies where security is paramount, the cost of conducting a safe exchange of keys, perhaps by arranging a face-to-face meeting, may be worth it. For other types of communications, such as the exchange of messages or credit information over the Internet, such measures are clearly not feasible. In 1976, Whitfield Diffie and Martin Hellman proposed a new class of encryption algorithms they called public key encryption. The idea behind public key encryption is to assign each person a pair of keys, one of which is public and the other private. A message encoded with one of these keys requires the other one for decoding. Thus, if you know someone's public key, you can encode a message that only they can decode using their private key. The result is that you can send a secure message to someone without having share any secret keys - each person maintains their own private key that only they know. Public and private keys can also be used to verify the identity of the sender. If the sender also encodes the message using their private key, then the recipient can decode the message using the sender's public key onto verify that they are indeed the sender (see Figure 8.7). The RSA algorithm, invented in 1977 by Ron Rivest, Adi Shamir, and Len Adleman at MIT, was the first practical implementation of a public key encryption algorithm and is the basis of almost all secure communications that occur over the Internet and Web.
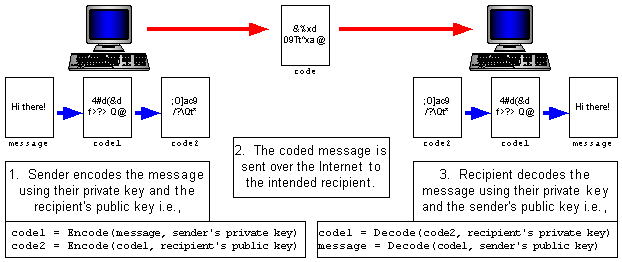
|
The Architecture subfield is concerned with methods of organizing hardware components into efficient, reliable systems. As we saw in Chapter 1, most computers utilize the same basic architecture, known as the von Neumann architecture. Even within this model, new technologies and techniques are constantly being developed to improve system performance and capabilities. For example, Chapter 6 followed the development of computers, showing how new technologies for switching electrical signals (relays --> vacuum tubes --> transistors --> integrated circuits) made computers smaller, cheaper, and more accessible. Other improvements in areas such as microchip manufacturing (see Chapter 16), memory storage and access, and input/output methods, have led to more powerful and usable systems.
In recent years, computer architectures that differ from the von Neumann model have been developed and used effectively in certain application areas. Parallel computing, as the name suggests, is an approach where multiple processors work in parallel, sharing the computational load. Ideally, doubling the number of processors in a system ought to cut the time it takes to accomplish a task in half, since twice as many processors are able to work on subtasks at the same time. In practice, however, not all tasks are well suited to parallel computing. For example, if an algorithm involves a sequence of steps, each of which depends on the results from the previous step, then the steps must be executed in the order specified and additional processors will be of little help. Even when a task can be divided, there are overhead costs in coordinating the processors, as some may need to share information or perform critical steps in a specific order.
Knowing how and when parallel computing can be applied to effectively solve problems requires an understanding of theory (in order to effectively divide the algorithmic steps among processor) and software methods (in order to specify control information within programs), as well as the design and implementation of hardware systems. A common use of parallel computing is in Web servers. Recall that a Web server manages pages and other resources (such as images and sound files), and sends those resources to other computers that request them. Since a Web server may be called upon to service many requests in a short period of time, and each of those requests is relatively independent, many Web servers utilize multiple processors to share the load. A more extreme example of parallel computing is Deep Blue, the chess-playing computer developed at IBM. Deep Blue has 32 general-purpose processors and 512 special-purpose chess processors, each of which can work in parallel to evaluate potential chess moves. Together, these processors are able to consider an average of 200 million possible chess moves in a second! In 1997, Deep Blue became the first computer to defeat a world champion in a chess tournament, defeating Gary Kasparov in six games.

|
The subfield of Operating Systems and Networks is concerned with mechanisms that control the hardware and software components of computer systems. As we saw in Chapter 1, an operating system is the collection of software that coordinates the hardware and programs on a single computer. In the 1950s, operating systems were relatively simple, allowing other pieces of software to manage system resources such as printers or external memory devices. In the 1960s, operating systems introduced time-sharing, which allowed multiple users to share the computing power of a machine. This was accomplished by giving each user a share of the processor, swapping users in and out so quickly that it appears to the human observer that each is executing simultaneously. In the 1970s, the idea of time-sharing was extended to multi-tasking, where a single user could have multiple programs executing simultaneously. In addition to these features, modern operating systems such as Windows XP, Mac OS X, and UNIX, provide an intuitive graphical user interface (GUI) that allows the user interact with programs and hardware devices through windows, icons, and menus.
While an operating system controls the software and hardware components of a single machine, computers today are rarely isolated. Instead, computers are connected in networks that allow for them to communicate with each other and share resources. A network of computers may be classified as either a Wide Area Network (WAN) or Local Area Network (LAN). A WAN connects computers over long distances and thus must build in controls for routing messages and adapting to failures that will inevitably occur. As we saw in Chapter 6, the Internet utilizes a distributed architecture and packet-switching to construct an effective and robust WAN. When connecting computers over short distances, say within the same room or building, the overhead of the network can be minimized. In fact, the most popular technology for constructing LANs, Ethernet, is quite simple in its form.
In an Ethernet network, all of the computers that need to communicate with one another are connecting to a common communications line, known as the Ethernet Bus (Figure 8.9). The computers all share the Ethernet Bus, and must take turns transmitting messages over it. Since the network is small, there is no need for an elaborate mechanism that directs messages to their intended recipients. Instead, each message is broadcast to all computers on the network via the Ethernet Bus, and it is up to the recipient to recognize which messages are directed to it and which can be ignored. Because of its simplicity, Ethernet networks are able to provide impressive communication speeds: usually either 10M bits per second or 100M bits per second, depending on the type of Bus used and the distances covered.
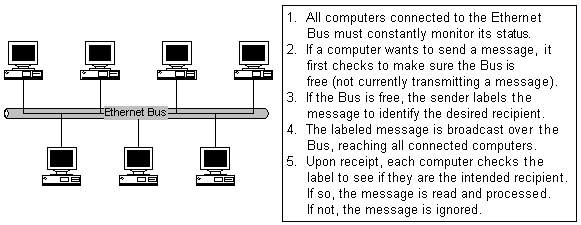
|
Software Engineering is the subfield of computer science concerned with developing effective software systems. The development and support of computer software has grown to be a major factor in the global, information-based economy of the 21st century. According to the research firm International Data Corp. (IDC), worldwide sales of packaged software grew in the 1990s at an average of 12% per year. That growth tapered off at the end of the decade due to the downturn in the economy, but the IDC still estimates worldwide sales of $183 billion in 2003, up 6% from the $172 billion registered in 2002. The United States is estimated to hold approximately 70% of the worldwide software market.
While the demand for software continues to grow, increases in programmer productivity threaten to lag behind. It would be nice if there were an equivalent to Moore's Law (which states that the number of transistors that can be placed on a computer chip doubles every year or two) for software. However, it is not reasonable to expect programmers to double their production in a year. In addition, doubling the number of programmers on a project adds many complications, with personnel management and coordination becoming increasingly complex as project size grows. Large software projects can reach millions of lines of code, requiring large teams of programmers and analysts. For example, the Windows XP operating system, released in 2001, consisted of over 45 million lines of code. If programs of this size are to be developed quickly, cheaply, and reliably, coordination and reuse are keys. The design of large systems must be coordinated among large teams of people and lead to seamless integration, with the reuse of existing code taking place whenever possible. Various software development methodologies have been developed and used in industry for managing personnel and creating quality software. In order to be effective, a development methodology must address all aspects of the software life cycle (Figure 8.10).
|
As the name suggests, software engineering is primarily about software. However, the other computer science themes, hardware and theory, also play key roles. A developer of software must have a thorough understanding of the hardware that will execute that software. In addition, developing efficient software requires a theoretical understanding of algorithms and their behavior.
Perhaps one of the most well known subfields of computer science is Artificial Intelligence, which seeks to make computers exhibit more human like characteristics - the ability to see, hear, speak, even reason and think. In his 1950 paper, Computing Machinery and Intelligence, Alan Turing predicted that machines would be programmed to rival humans in intelligence by the end of the 20th century (Figure 8.11). While this ultimate goal is still far out of reach, much progress has been made in areas such as robotics, machine vision, and speech recognition. Expert systems, programs that encapsulate the knowledge and reasoning of experts in specific domains such as medical diagnosis, have been highly successful in practice. Research into topics such as machine learning and knowledge representation have not only produced practical results, but have also helped further our understanding of how humans reason and learn. Neural computing, the design of computers based on the architecture of the brain, is an especially promising area of research, both for its technical applications and its potential for helping us to understand our own physiology.
|
Brooks, Frederick P., Jr. The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition. Addison Wesley, Reading, MA,1995.
Deep Blue. IBM Research. Online at http://www.research.ibm.com/deepblue/.
Denning, Peter. Computer Science: The Discipline. In Encyclopedia of Computer Science, 4th Edition, A. Ralston, E. Reilly, and D. Hemmendinger, editors, Nature Publishing Group, New York, 2000. Online at http://cne.gmu.edu/pjd/PUBS/cs99.pdf.
Hodges, Andrew. Alan Turing: The Enigma. Walker and Company, New York, 2000.
Joint IEEE Computer Society/ACM Task Force for CC2001. Computing Curricula 2001. ACM Journal of Educational Resources in Computing 1(3), 2001. Online at http://www.acm.org/sigcse/cc2001/.
Knuth, Donald. The Art of Computer Programming, Volume 1: Fundamental Algorithms, 3rd Edition. Addison-Wesley, Boston, 1997.
Simon, Herbert. The Sciences of the Artificial, 3rd Edition. MIT Press, Cambridge, 1996.
Stallings, William. Cryptography and Network Security: Principles and Practice, 2nd Edition. Prentice Hall, Upper Saddle River, 1999.
Stewart, N.F. Science and Computer Science. ACM Computing Surveys 27(1), 1995. Extended version online at http://www.iro.umontreal.ca/~stewart/science_computerscience.pdf.
Turing, Alan. Computing Machinery and Intelligence. Mind, vol. LIX(236), 1950.